A methodological framework for the use of AI tools in automated workflows for generating validated and structured historical datasets
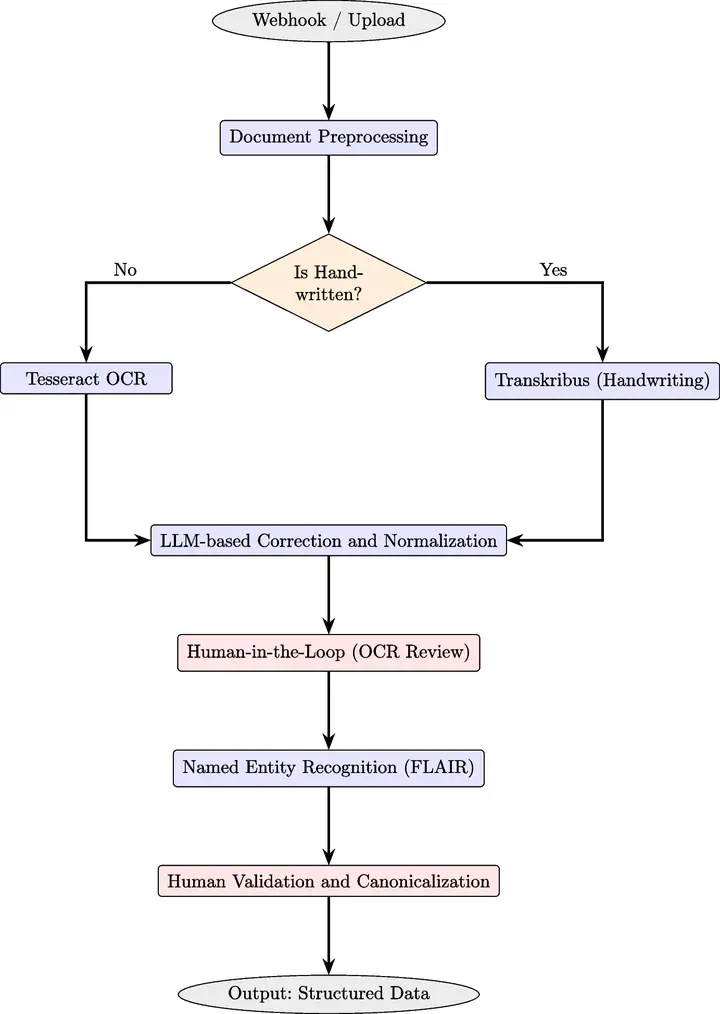 Schematic overview of the automated workflow for OCR processing, LLM-assisted correction, and entity extraction, implemented through the n8n orchestration framework
Schematic overview of the automated workflow for OCR processing, LLM-assisted correction, and entity extraction, implemented through the n8n orchestration frameworkResumen
The growing availability of digitized historical collections has enabled large-scale computational research; however, transforming heterogeneous and noisy textual data into structured and analyzable formats remains a major challenge within the Digital Humanities. This article presents a reproducible workflow for historical text processing that integrates Optical Character Recognition (OCR), Large Language Models (LLM)-assisted post-correction, and Named Entity Recognition (NER) into a unified pipeline. Implemented within the n8n automation framework, the workflow emphasizes transparency, modularity, and human-in-the-loop validation, enabling scholars to maintain interpretive control over data transformation. The pipeline is evaluated on five historical corpora in Spanish (eighteenth and nineteenth centuries), demonstrating significant reductions in Character and Word Error Rates (up to -93.5% and -66.8% respectively) through lightweight, open-weight LLMs (Gemma 3 27B, Qwen 2.5 32B, LLaMA 3 70B). NER performance using FLAIR achieves F1 scores above 0.96 for persons and organizations, and a semantic-level similarity evaluation is added through CoNES to assess distributed lexical recovery. Beyond reporting benchmarks, the study reflects on the epistemic implications of automated processing in historical research and argues that reproducible data pipelines are essential infrastructures for scaling relational analyses such as co-entity networks and computational historiography. All results contribute toward a transparent methodological model that bridges humanistic inquiry and computational automation while preserving scholarly traceability.
Edgardo Galán Vásquez
Investigador Asociado C
Estoy interesado en las lineas de investigación de Ciencia de datos aplicada a datos biológicos, Bioinformática, Biología de sistemas y redes complejas.