Mineria de datos biológicos
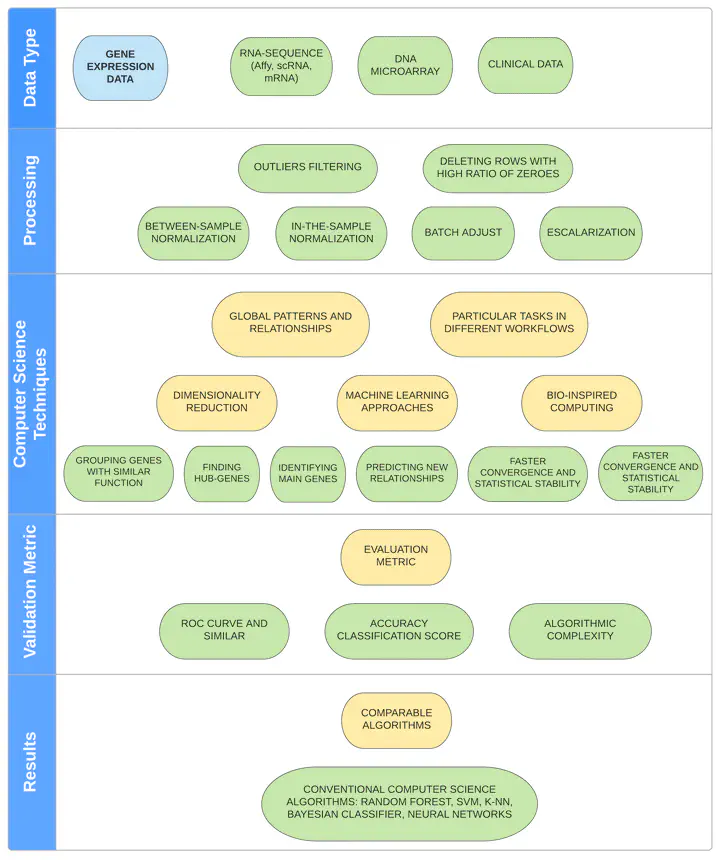
Obtener, preprocesar y procesar datos de alto rendimiento
El término Minería de datos biológicos ha cobrado relevancia en los últimos años, debido a la necesitad de procesar y analizar los grandes volúmenes de información generados a partir de experimentos biológicos. Podemos definir Minería de datos como la tarea no trivial de extraer información implícita previamente desconocida y potencialmente útil a partir de bases de datos. Las técnicas principales para la minería de datos incluyen: clasificación, clustering, detección de valores atípicos, reglas de asociación, análisis de secuencias, análisis de serie de tiempo y minería de textos. Una de las bases de datos biológicos más grande, es el National Center for Biotechnology Information (NCBI) que contiene información de datos a partir de experimentos High-throughput como microarreglos y secuenciación de ARN. Se estima que contiene más de 36 pentabytes (10^15 bytes) de información. Por lo que nuevas aproximaciones en bioinformática, biología de sistemas y ciencia de datos permiten procesar, visualizar y analizar esta información, para generar nuevo conocimiento. En este sentido, desarrollamos diferentes workflows para descargar, transformar, procesar y analizar los datos crudos almacenados en el NCBI.
Edgardo Galán Vásquez
Investigador Asociado C
Estoy interesado en las lineas de investigación de Ciencia de datos aplicada a datos biológicos, Bioinformática, Biología de sistemas y redes complejas.